- Published on
eBPF + OpenTelemetry:适用于任何应用的零代码自动化测量
- Authors

- Name
- 俞凡
本文介绍如何将 eBPF 与 OpenTelemetry 结合,实现自动化、零代码的分布式追踪和可观测性系统,了解 Odigos、Beyla 和 OpenTelemetry eBPF 等工具的工作原理、适用场景以及如何在生产环境中设置。原文:Using eBPF with OpenTelemetry: Zero-Code Auto-Instrumentation for Any Application
如果能在所有服务间实现完整的分布式追踪,而无需添加一行仪表盘代码,怎么样?
传统 OpenTelemetry 仪表盘需要添加 SDK、配置导出器,并用 span 包装代码。虽然功能强大,但需要付出不少努力,尤其是系统中有数十种不同语言的服务时。
eBPF 完全改变了这一模式。通过从 Linux 内核观察应用,基于 eBPF 的工具可以自动生成兼容 OpenTelemetry 的追踪、指标和配置文件,而无需触及应用代码 。
本文将介绍如何将 eBPF 与 OpenTelemetry 结合,实现强大的零代码可观测性。
1. 问题:大规模仪表盘
传统 OpenTelemetry 仪表盘遵循以下模式:
- 为每个服务添加 OTel SDK
- 配置导出器
- 测量入口点(HTTP 处理程序,gRPC 方法)
- 为重要操作添加 span
- 跨服务边界传播上下文
- 每个服务、每种语言都要重复
对于只有少量服务的小团队来说,还算可以管理。但请考虑:
| 场景 | 挑战 |
|---|---|
| 50+ 微服务 | 需要数周时间集成跨所有服务的 SDK |
| 多语言技术栈 | Go、Python、Node.js、Java、Rust 等不同的 SDK…… |
| 遗留服务 | 代码不容易修改,没人愿意碰 |
| 第三方服务 | 无法访问源代码 |
| 快速部署 | 新服务出现的速度比测量它们的速度还快 |
结果呢?可观测性缺口。有些服务有追踪,有些没有。未安装测量的服务中断上下文传播。系统一定程度上正在裸跑。
2. eBPF 如何实现自动化测量
eBPF 通过从应用外部 —— 内核层面观察应用来解决这个问题。
eBPF 能看到什么
由于 eBPF 会钩入内核函数和系统调用,可以观察到:
| 层 | eBPF 看见 |
|---|---|
| 网络 | 每一次 TCP 连接、HTTP 请求/响应、DNS 查询 |
| 系统调用 | 文件 I/O,进程创建,内存分配 |
| 用户功能 | 函数通过 uprobe 进入/退出(如果有符号) |
| 语言运行时 | Go、Node.js、Python、Java 运行时内部结构 |
这些如何成为 OpenTelemetry 数据
基于 eBPF 的自动化测量工作原理:
- 将探针附加到已知入口点(HTTP 库、gRPC 处理器、数据库驱动程序)
- 从请求中提取上下文(从头部提取追踪 ID、请求元数据)
- 利用内核时间戳测量时序
- 关联相关请求/响应对
- 导出为标准 OpenTelemetry Protocol(OTLP)数据
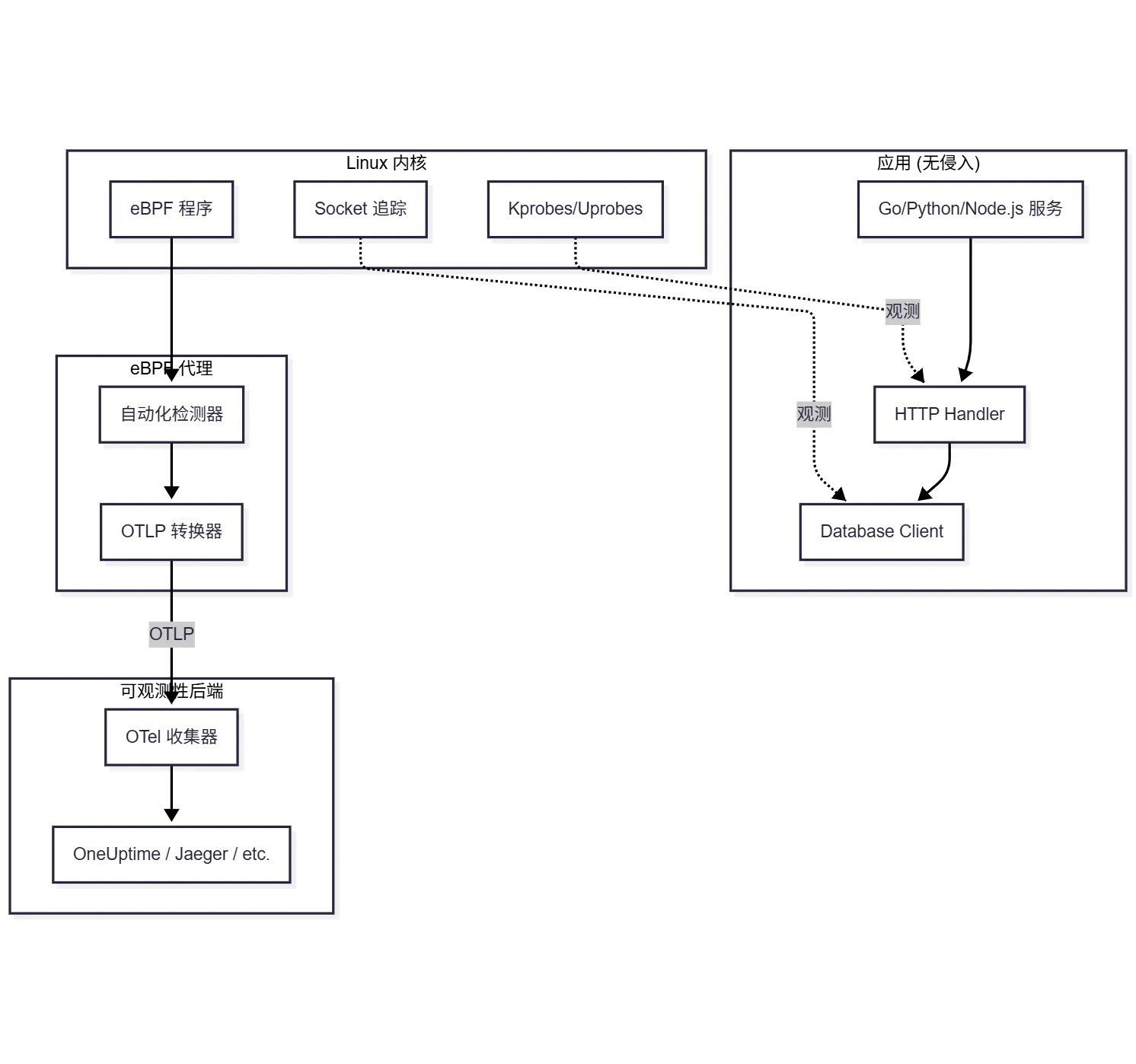
3. eBPF + OpenTelemetry 架构
典型生产配置如下:
组件
| 组件 | 职责 |
|---|---|
| eBPF 代理 | 运行在每个节点上,连接 eBPF 程序,生成遥测数据 |
| OTel 收集器 | 接收、处理 OTLP 数据,并导出到后端 |
| 后端 | 存储和可视化追踪/指标(OneUptime、Jaeger、Tempo) |
部署模式
模式 1:DaemonSet(Kubernetes)
# 运行在每个 node 上的 eBPF 代理
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ebpf-auto-instrumenter
spec:
selector:
matchLabels:
app: ebpf-agent
template:
spec:
hostPID: true # eBPF 需要
hostNetwork: true # 网络追踪需要
containers:
- name: agent
securityContext:
privileged: true # eBPF 需要
模式 2:Sidecar(每个 Pod 一个)
# eBPF 代理作为 sidecar (更为隔离,更多开销)
spec:
containers:
- name: my-app
image: my-app:latest
- name: ebpf-sidecar
image: ebpf-agent:latest
securityContext:
privileged: true
模式 3:独立(非 Kubernetes)
# 直接在主机上运行
sudo ./beyla --config config.yaml
4. 工具比较:Odigos vs Beyla vs Pixie
下面比较几种将 eBPF 与 OpenTelemetry 结合起来的工具。
Grafana Beyla
| 特色 | 详情 |
|---|---|
| 重点 | HTTP/gRPC 自动监测 |
| 语言 | Go, Python, Node.js, Java, Rust, .NET, Ruby |
| 输出 | OTLP (追踪 + 指标) |
| 部署 | 独立二进制或 Kubernetes |
| 许可证 | Apache 2.0 |
| 最佳实践 | 简单部署,Grafana 技术栈用户 |
Odigos
| 特色 | 详情 |
|---|---|
| 重点 | 带上下文传播的全分布式追踪 |
| 语言 | Go, Python, Node.js, Java, .NET |
| 输出 | OTLP(追踪) |
| 部署 | Kubernetes 原生(operator) |
| 许可证 | Apache 2.0 |
| 最佳实践 | Kubernetes 环境,分布式追踪 |
Pixie
| 特色 | 详情 |
|---|---|
| 重点 | 全栈可观测性,带集群内存储 |
| 语言 | Go, C/C++, Python, Node.js, Java, Rust |
| 输出 | Pixie 格式(可导出为 OTel) |
| 部署 | 仅限 Kubernetes |
| 许可证 | Apache 2.0 |
| 最佳实践 | 调试、临时查询、全面可视化 |
快速决策指南
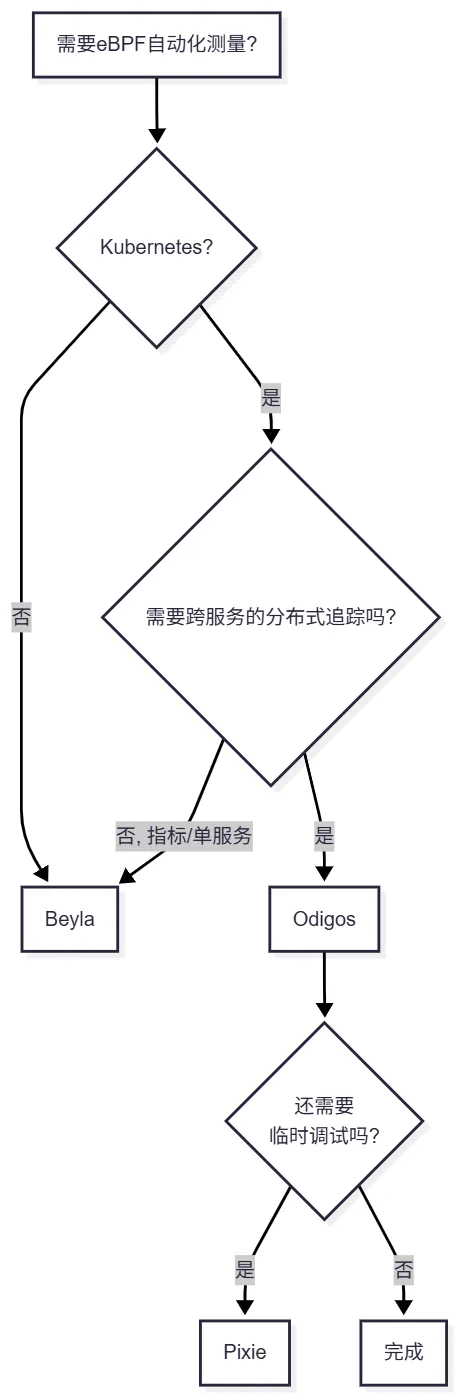
5. 设置 Beyla(Grafana 的 eBPF 自动化测量)
Beyla 是入门基于 eBPF 的 OpenTelemetry 测量的最简单方式。
前置条件
- Linux 内核 5.8+(支持 BTF)
- Root/privileged 访问
- 目标应用程序正在运行
安装
# 下载最新版本
curl -LO https://github.com/grafana/beyla/releases/latest/download/beyla-linux-amd64.tar.gz
tar xzf beyla-linux-amd64.tar.gz
sudo mv beyla /usr/local/bin/
配置
创建 beyla-config.yaml:
# beyla-config.yaml
open_port: 8080 # 测量进程监听端口
# 或目标的可执行名称
# executable_name: "my-service"
# 或进程 ID
# pid: 12345
# OTLP 导出配置
otel_traces_export:
endpoint: http://localhost:4317 # OTel 收集器
otel_metrics_export:
endpoint: http://localhost:4317
# 可选: 添加资源参数
attributes:
kubernetes:
enable: true # 自动检测 K8s 元数据
# 采样 (可选)
traces:
sampler:
name: parentbased_traceidratio
arg: "0.1" # 10% 采样
运行 Beyla
# 通过配置文件执行
sudo beyla --config beyla-config.yaml
# 或者通过环境变量
sudo BEYLA_OPEN_PORT=8080 \
OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4317 \
beyla
Kubernetes 部署
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: beyla
namespace: observability
spec:
selector:
matchLabels:
app: beyla
template:
metadata:
labels:
app: beyla
spec:
hostPID: true
serviceAccountName: beyla
containers:
- name: beyla
image: grafana/beyla:latest
securityContext:
privileged: true
runAsUser: 0
env:
- name: BEYLA_OPEN_PORT
value: "8080,3000,9090" # 测量端口
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: "http://otel-collector.observability:4317"
- name: BEYLA_KUBE_METADATA_ENABLE
value: "true"
volumeMounts:
- name: sys-kernel
mountPath: /sys/kernel
readOnly: true
volumes:
- name: sys-kernel
hostPath:
path: /sys/kernel
Beyla 采样数据
运行后,Beyla 会自动生成:
追踪:
- HTTP 服务器 span(方法、路径、状态、时长)
- HTTP 客户端 span(外出请求)
- gRPC span(方法,状态)
- SQL 查询 span(如果使用支持的驱动)
指标:
http.server.request.duration(直方图)http.server.request.body.sizehttp.client.request.durationrpc.server.durationrpc.client.duration
6. 为 Kubernetes 设置 Odigos
Odigos 提供了更全面的分布式追踪,并实现了自动上下文传播。
安装
# 安装 Odigos CLI
brew install odigos-io/homebrew-odigos-cli/odigos
# 或者直接下载
curl -LO https://github.com/odigos-io/odigos/releases/latest/download/odigos-cli-linux-amd64
chmod +x odigos-cli-linux-amd64
sudo mv odigos-cli-linux-amd64 /usr/local/bin/odigos
部署到 Kubernetes
# 在集群里安装 Odigos
odigos install
# 创建:
# - odigos-system namespace
# - Odigos operator
# - Instrumentor DaemonSet
# - OTel Collector (可选)
配置目的地
# 添加可观测性后端
odigos ui
# 或通过 CLI
odigos destination add oneuptime \
--endpoint https://otlp.oneuptime.com \
--api-key YOUR_API_KEY
测量命名空间
# 测量命名空间中的所有工作负载
odigos instrument namespace my-app-namespace
# 或指定工作负载
odigos instrument deployment my-service -n my-namespace
Odigos 运作方式
Odigos 比简单的 eBPF 追踪更智能:
- 语言检测:自动检测运行时(Go、Java、Python 等)
- 合适的测量方式:Go 使用 eBPF,Java/Python 注入代理
- 上下文传播:确保跨越服务边界追踪上下文
- 无代码更改:所有注入均发生在运行时
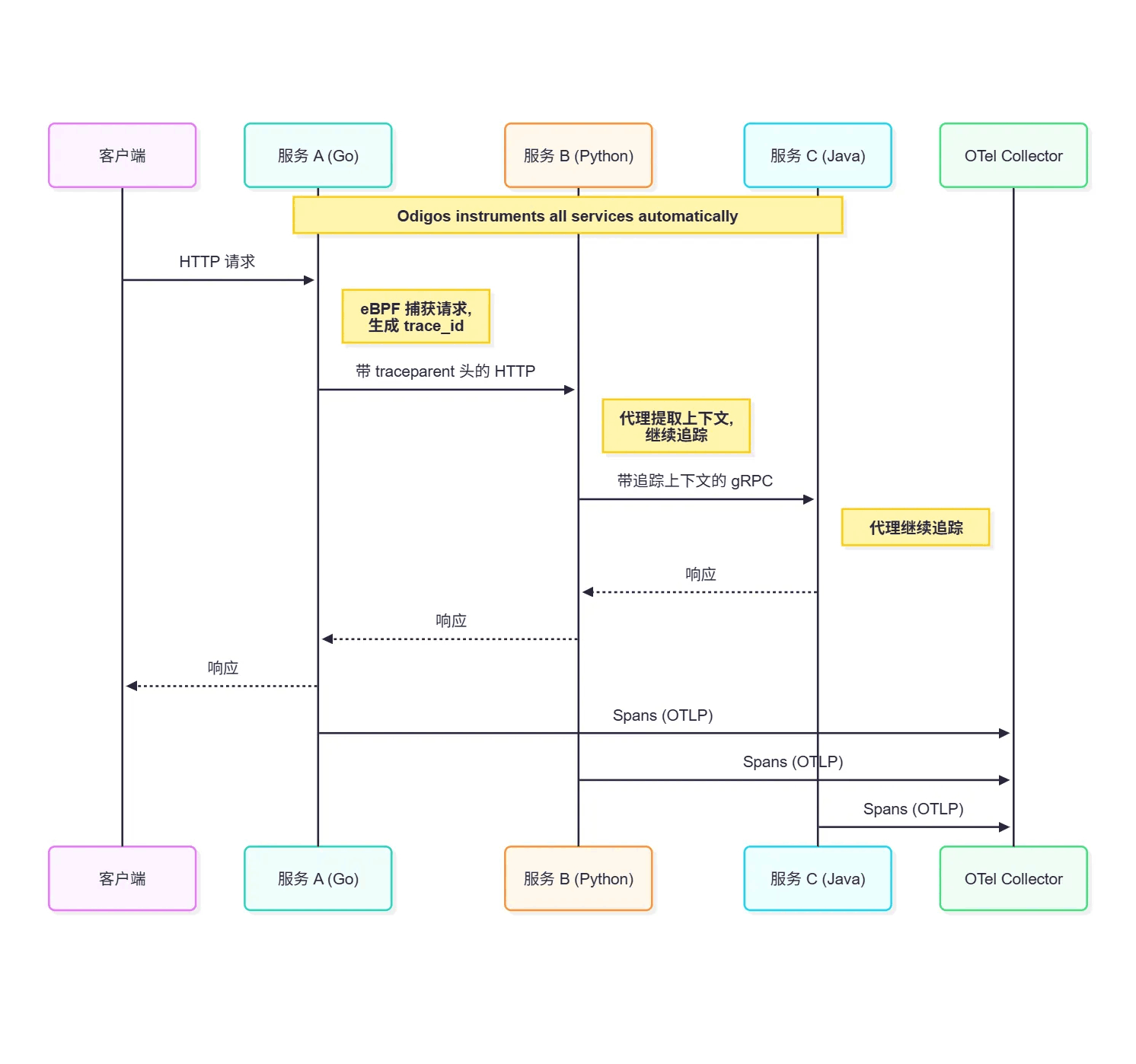
7. 自动获取的内容
以下是基于 eBPF 工具能自动获取或者不能获取的内容:
自动获取
| 信号 | 详情 |
|---|---|
| HTTP 服务器请求 | 方法、路径、状态码、时长、消息头 |
| HTTP 客户端请求 | 发送请求,含目的地和时间 |
| gRPC 调用 | 方法、状态、时长(包括服务器和客户端) |
| 数据库查询 | 查询文本、时长、数据库类型(因工具而异) |
| DNS 查询 | 域、查询时间、结果 |
| TCP 连接 | 源、目的、传输字节数 |
| TLS 握手 | 证书信息,握手时间 |
部分获取(因工具/语言而异)
| 信号 | 局限性 |
|---|---|
| 消息队列 | Kafka/RabbitMQ 的支持各不相同,可能需要手动设置 |
| 自定义协议 | 需要特定工具的支持 |
| 内部函数调用 | 只有在符号信息可用的情况下 |
| 业务逻辑上下文 | 无法推断用户 ID、订单 ID 等信息 |
无法获取(需要手动测量)
| 信号 | 为什么 |
|---|---|
| 自定义 span 属性 | eBPF 不知道业务域 |
| 应用错误 | 异常详情,stack trace(部分) |
| 自定义指标 | 业务关键绩效指标(KPI),转化率 |
| Baggage/Context | 自定义传播数据 |
8. 将 eBPF 数据与手动测量进行关联
最佳方法通常是混合式:基础覆盖用 eBPF,重要细节用手动测量。
策略:分层测量
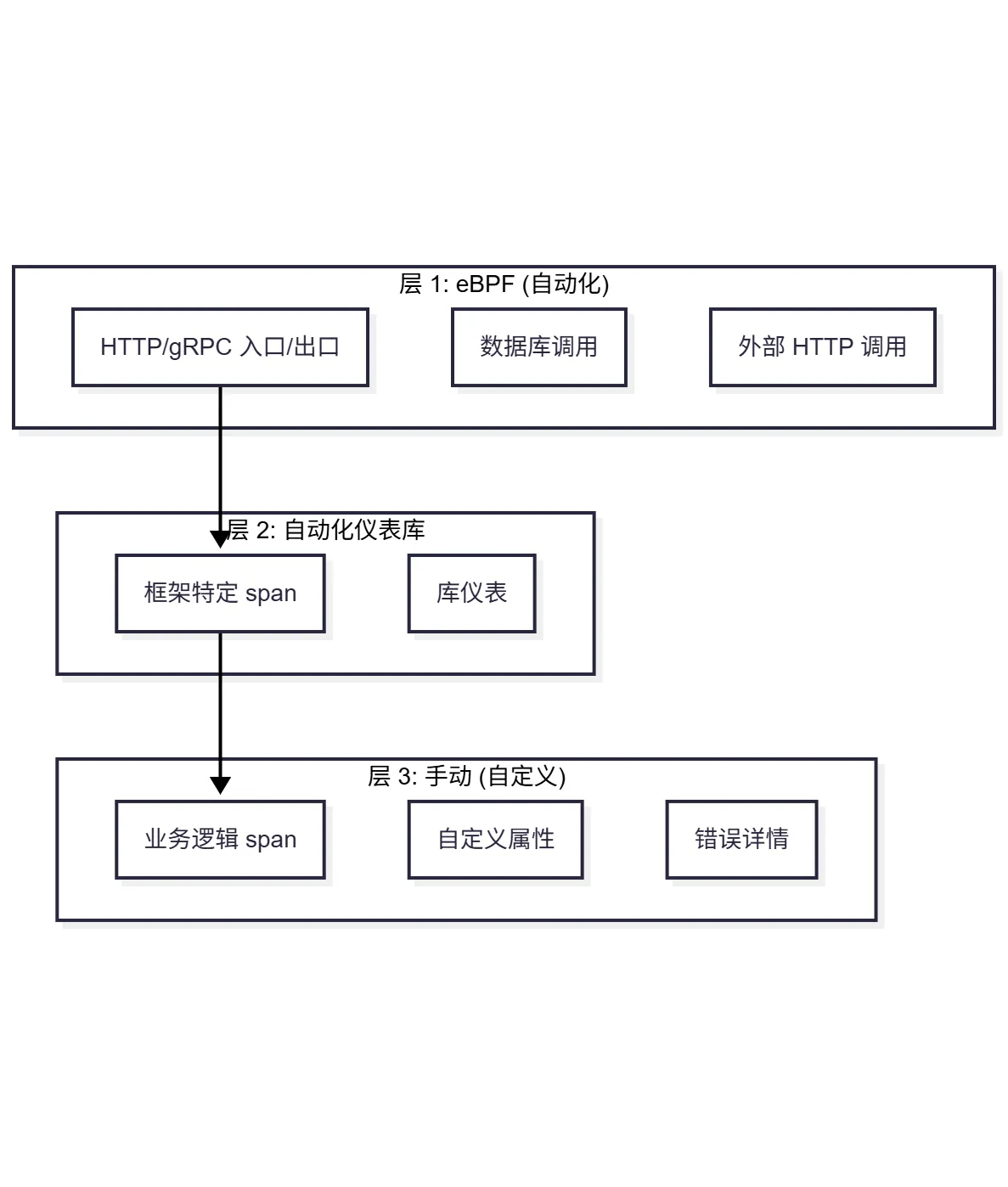
示例:混合配置
// Go 服务 - eBPF 自动捕获 HTTP 处理
// 为重要业务逻辑添加手动 span
func (s *OrderService) CreateOrder(ctx context.Context, req *OrderRequest) (*Order, error) {
// eBPF已经获取:HTTP POST /orders、计时、状态
// 业务逻辑细节的手动 span
ctx, span := tracer.Start(ctx, "order.validate")
err := s.validateOrder(ctx, req)
span.End()
if err != nil {
// 手动:添加 eBPF 看不到的错误细节
span.RecordError(err)
span.SetStatus(codes.Error, "validation failed")
return nil, err
}
// eBPF 自动捕获数据库调用
// 手动:添加业务上下文
ctx, span = tracer.Start(ctx, "order.save")
span.SetAttributes(
attribute.String("order.customer_id", req.CustomerID),
attribute.Float64("order.total", req.Total),
attribute.Int("order.items_count", len(req.Items)),
)
order, err := s.repo.Save(ctx, req)
span.End()
return order, err
}
确保相关性有效
为了让 eBPF span 和手动 span 出现在同一条追踪中:
- 相同的 Trace ID:eBPF 工具从输入请求中提取
traceparent - 上下文传播:手动 span 必须使用相同的上下文
- 一致导出:eBPF 和手动测量都导出到同一个收集器
# OTel Collector 配置合并两个源
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
batch:
timeout: 1s
# 添加一致的资源属性
resource:
attributes:
- key: deployment.environment
value: production
action: upsert
exporters:
otlp:
endpoint: https://oneuptime.com/otlp
headers:
x-oneuptime-token: ${ONEUPTIME_TOKEN}
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, resource]
exporters: [otlp]
9. 性能开销
关键问题: 运行基于 eBPF 的自动化测量的成本是多少?
测量额外开销
| 工具 | CPU 开销 | 内存 | 时延影响 |
|---|---|---|---|
| Beyla | 1-3% | ~50-100MB | < 1ms |
| Odigos | 2-5% | ~100-200MB | < 2ms |
| Pixie | 2-5% | ~500MB-1GB | < 1ms |
注意:实际开销因工作负载、采样率和追踪端点数量而异。
增加额外开销的因素
| 因素 | 影响 | 缓解措施 |
|---|---|---|
| 高请求量 | 更多 eBPF 事件待处理 | 增加采样 |
| 追踪太多端点 | 连接太多探针 | 要有选择性 |
| 全载荷捕获 | 用于复制数据的内存/CPU | 禁用或限制 |
| 低采样率 | 更多数据需导出 | 使用头部采样 |
降低开销
# Beyla 示例: 通过采样降低开销
traces:
sampler:
name: parentbased_traceidratio
arg: "0.01" # 1% 采样
# 隔离高数据量、低价值的端点
routes:
ignored:
- /health
- /ready
- /metrics
10. 局限性及何时使用手动测量
eBPF 自动测量功能强大,但并非魔法,需要知道取舍。
在以下情况下使用 eBPF 自动化测量:
✅ 需要在多个服务中快速实现基线可观测性
✅ 不能修改应用代码(遗留版本,第三方代码)
✅ 需要一致的 HTTP/gRPC/数据库追踪,而不是每个服务单独设置
✅ 需要网络层面的可视化(连接、DNS)
✅ 身处混合语言的 Kubernetes 环境中
需要使用手动测量:
✅ 需要自定义业务属性(用户 ID、订单 ID、功能标志)。
✅ 需要详细的错误信息和 stack traces
✅ 需要自定义指标(业务关键绩效指标、特定事件的计数器)
✅ 追踪没有 eBPF 支持的非 HTTP 协议
✅ 需要跨服务上下文的 baggage 传播
✅ 要控制 span 名称和结构
eBPF 自动化测量的局限性
| 限制 | 详情 |
|---|---|
| 仅限 Linux | 不支持没有 Linux 内核的 Windows、macOS 或容器运行时 |
| 内核版本 | 需要 5.x 以上才能获得最佳效果,部分功能需要 5.8 以上 |
| 特权访问 | 必须提升权限运行(安全考虑) |
| 符号可用性 | 剥离符号的 Go 二进制可执行文件会降低可见度 |
| 加密流量 | TLS 检查需要额外设置 |
| 应用上下文 | 无法从网络数据推断业务含义 |
11. 最佳生产实践
安全考量
运行 eBPF 代理需要提升权限。降低风险:
# Kubernetes: 严格使用 RBAC
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: ebpf-agent-role
rules:
- apiGroups: [""]
resources: ["pods", "nodes"]
verbs: ["get", "list", "watch"]
# 避免授予不必要的权限
# 尽可能使用 seccomp 配置文件
securityContext:
seccompProfile:
type: RuntimeDefault
限制资源
containers:
- name: ebpf-agent
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 512Mi
过滤与抽样
# 不要追踪每件事 —— 专注于重要的事情
routes:
patterns:
- /api/* # Trace API calls
- /graphql # Trace GraphQL
ignored:
- /health # Skip health checks
- /metrics # Skip metrics endpoint
- /favicon.ico # Skip static assets
# 通过采样控制数据量
traces:
sampler:
name: parentbased_traceidratio
arg: "0.1" # 10% in production
逐步推广
# 从非生产环境开始
odigos instrument namespace staging
# 验证开销和数据质量
# 然后扩展到生产环境
odigos instrument namespace production
监控
# 导出 eBPF 代理指标
prometheus:
port: 9090
path: /metrics
# 代理有问题时告警
# - 高 CPU 使用率
# - 事件丢失
# - 导出失败
12. 结论
基于 eBPF 的自动化测量代表了可观测性的范式转变。通过将测量迁移到内核级,我们可以:
- 消除测量负担:不再按服务集成 SDK
- 实现全覆盖:观察任何应用,任何语言
- 减少盲点:发现那些被忽视的服务
- 加快上线速度:新服务可立即被观测到
但并不能完全取代传统测量。最佳可观测性策略结合了:
- eBPF 用于基线基础设施层级可视化
- 针对特定框架上下文的自动化测量库
- 为业务关键范围和自定义属性提供手动测量
像 Beyla 和 Odigo 这样的工具让入门变得前所未有的简单。如果应用运行在 Kubernetes 和 Linux 上,只需要几分钟就可以实现整个分布式追踪技术栈。
要点
- eBPF 通过从内核观测应用实现零代码仪表化
- OpenTelemetry 兼容性意味着 eBPF 数据会流入现有可观测栈
- 选择合适的工具:Beyla 简化应用,Odigos 支持 Kubernetes 分布式追踪,Pixie 负责调试
- 混合方法效果最佳:eBPF 用于覆盖,手动测量用于业务环境
- 开销低(1-5% CPU),但要监控并使用采样
- 安全问题:eBPF 需要特权,授权范围要适当
- 从小处开始:先从非生产环境开始,再扩展到生产环境
延伸阅读
What is eBPF and How Does It Work? —— 深入探讨 eBPF 基础知识
Traces and Spans in OpenTelemetry —— 理解分布式追踪
What are Metrics in OpenTelemetry? —— 指标基础
Logs, Metrics & Traces: The Three Pillars —— 完整的可观察性概述
Basics of Profiling —— 需要更深入的性能洞察时